


Before we quickly dive into the topic of HPA, we need to understand a few terms first.

The first among these is Deployment.
Deployment
Use Case
Deployments are suitable for stateless applications.
They are ideal for applications that can scale horizontally and do not require unique identifiers or stable network identities.
Key Features
It supports rolling updates and rollbacks, making it easy to update the application without downtime.
Scales horizontally by increasing or decreasing the number of replicas.
Can be used for applications with no requirements for stable network identities or unique hostnames.
Example Deployment YAML
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-container
image: nginx:latest
The second one to understand is StatefulSet.
StatefulSet
Use Case
StatefulSets are designed for stateful applications that require stable network identities and persistent storage.
Ideal for applications that need to maintain a unique identity, such as databases.
Key Features
Maintains a stable hostname for each pod, which is valuable for applications requiring persistent network identifiers.
Provides ordered and unique deployment and scaling of pods.
Supports automatic and manual rollouts.
Example StatefulSet YAML
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: my-statefulset
spec:
replicas: 3
serviceName: "my-statefulset"
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-container
image: nginx:latest
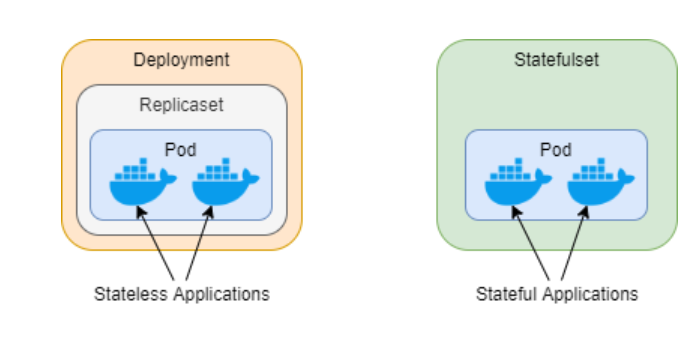
Key Differences
Network Identity
Deployment: Pods are not guaranteed to have stable network identities. Each pod can have a different IP address.
StatefulSet: Pods have stable network identities. Each pod gets a unique and predictable hostname.
Scaling
Deployment: Scales horizontally by increasing or decreasing the number of replicas.
StatefulSet: Scales horizontally but maintains a stable identity for each pod.
Pod Termination
Deployment: Pods can be terminated and replaced at any time during updates.
StatefulSet: Pods are terminated and replaced in a predictable order, which can be crucial for applications that rely on specific pod order.
Storage
Deployment: Generally used for stateless applications. Data is often stored externally (e.g., in a database).
StatefulSet: Designed for stateful applications and provides support for persistent volumes.
So the next question in mind is: how do we choose between these two?
Select StatefulSet or Deployment, depending on what your application needs. StatefulSet is the right option if you require consistent network identities and long-term storage, particularly for stateful applications like databases. Deployment is frequently more appropriate for stateless programs that can grow horizontally without depending on reliable network identities.
Now that we have understood these two, let’s grab the main content, the Horizontal Pod Autoscaler (HPA).
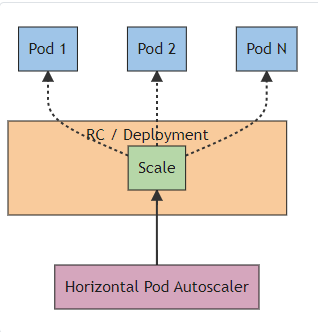
A Kubernetes feature called Horizontal Pod Autoscaler (HPA) dynamically modifies the number of pods that are running in a deployment or replica set based on metrics that are monitored, like CPU utilization or custom metrics. Making sure your application has adequate resources to manage a range of workloads effectively is the aim of HPA.
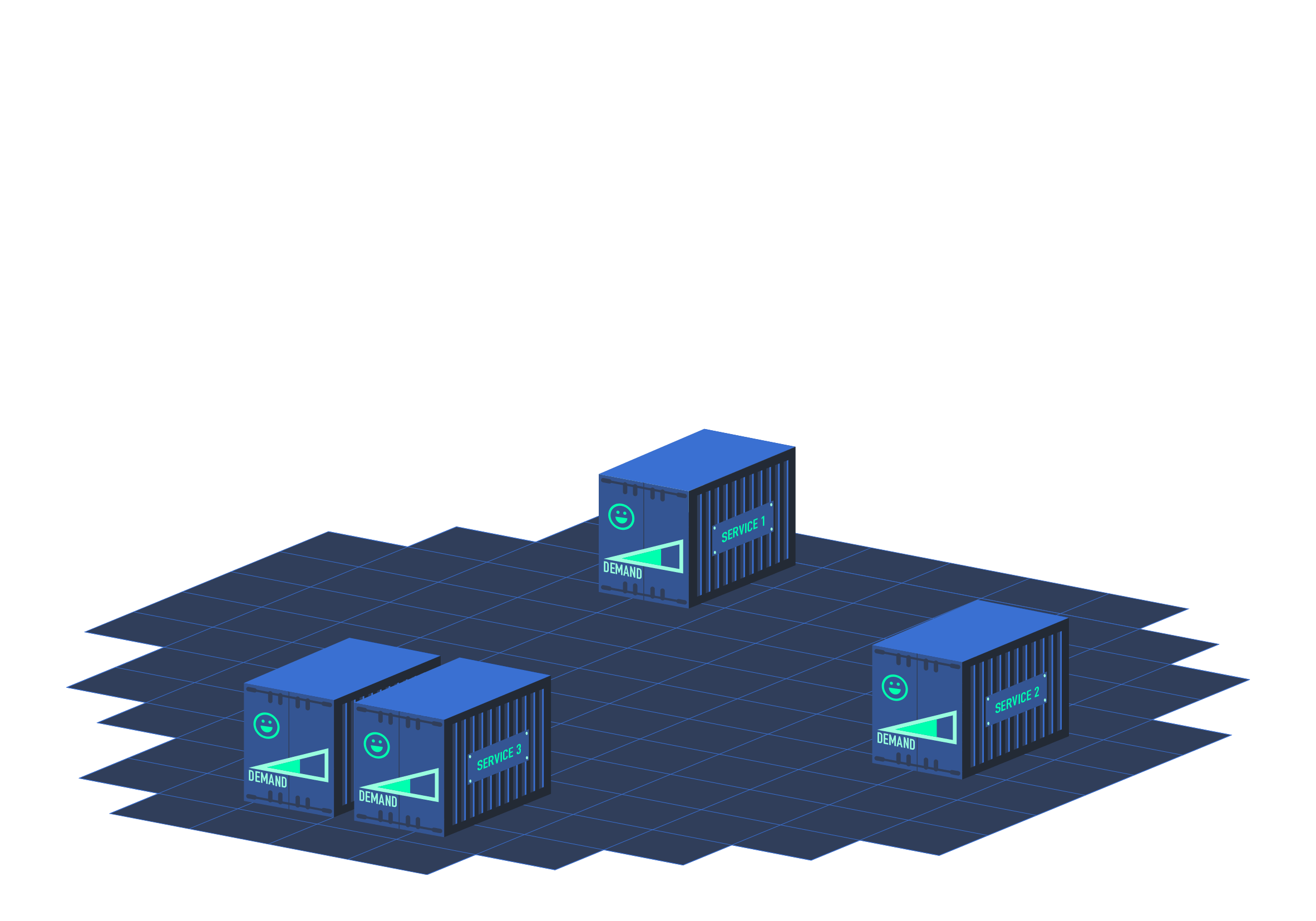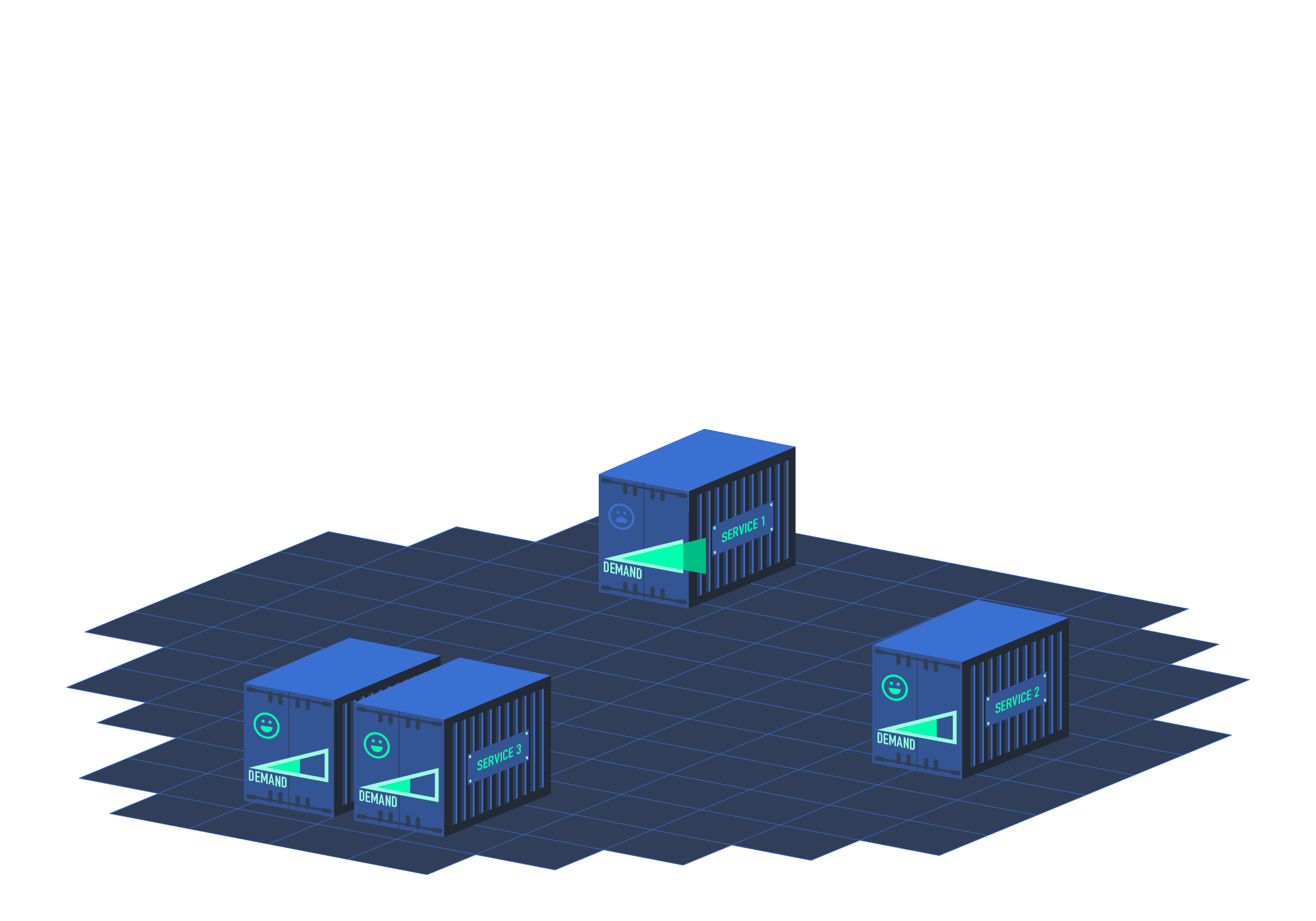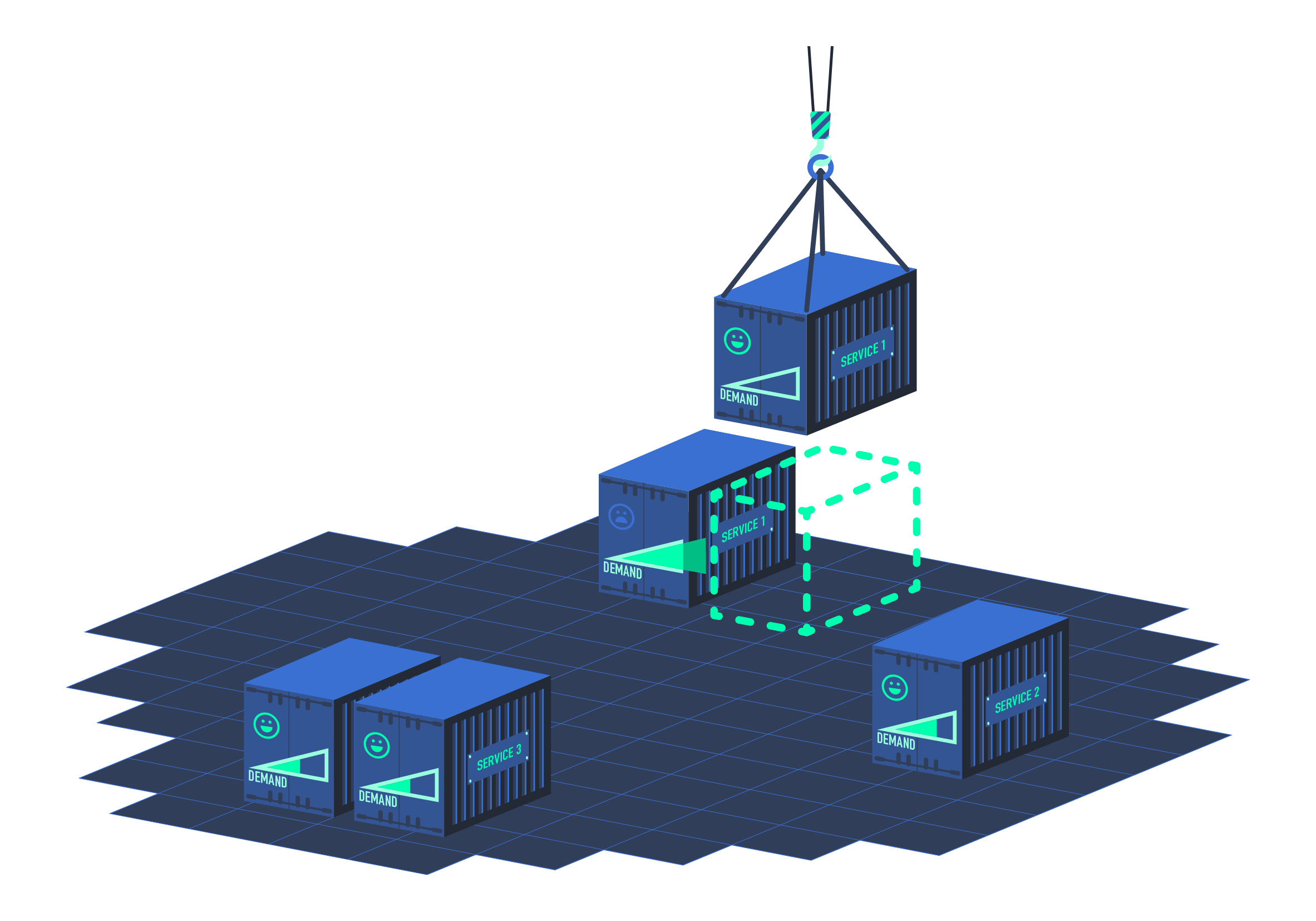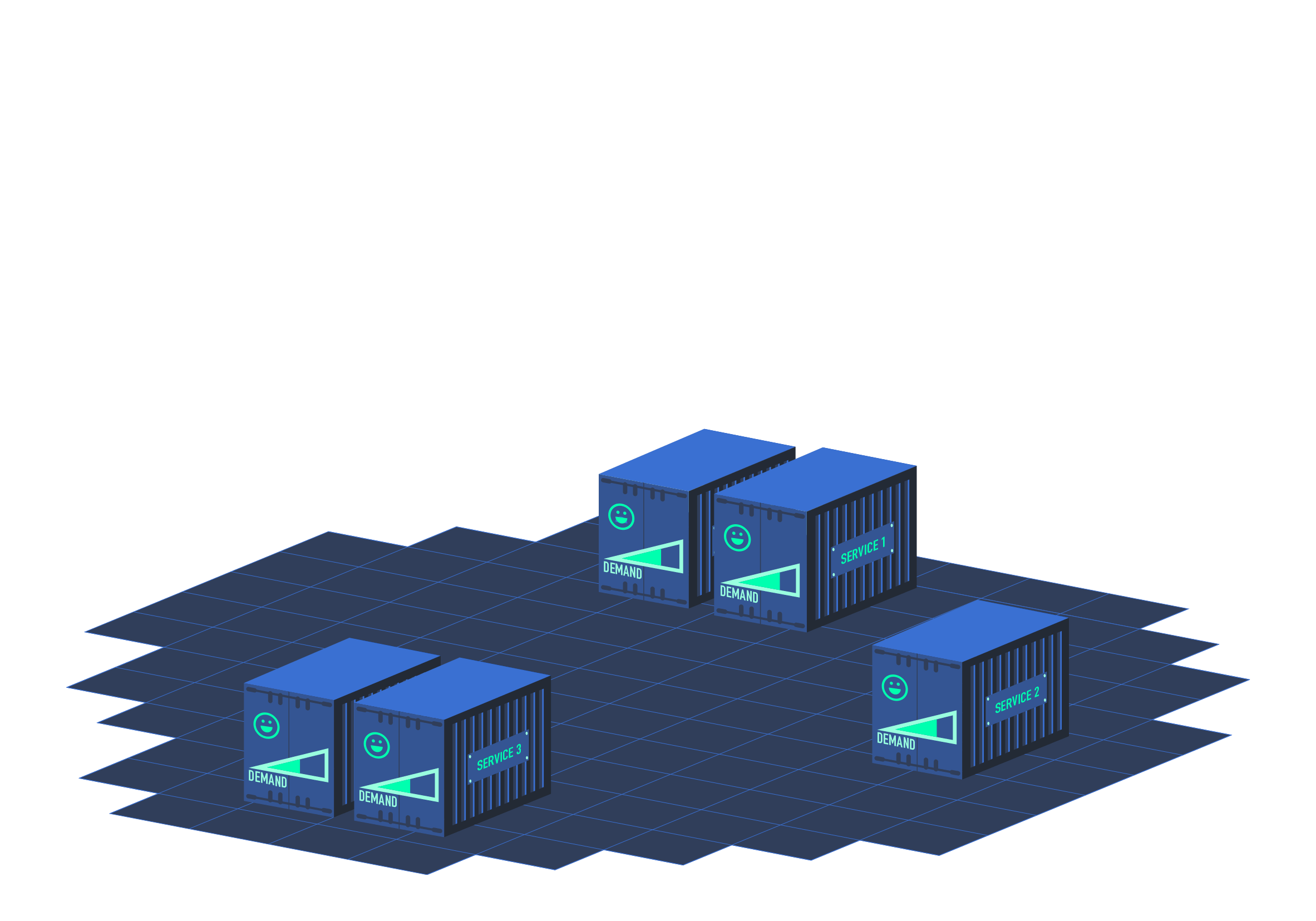
Key Features of HPA
Dynamic Scaling
- HPA automatically adjusts the number of replicas (pods) in a deployment based on observed metrics, allowing your application to scale in or out dynamically.
Metrics
- HPA supports both CPU-based and custom metrics for scaling decisions. CPU utilization is the most common metric used, but you can also configure HPA to scale based on metrics such as memory usage, application-specific metrics, or external metrics.
Configurable Metrics
- HPA allows you to define scaling policies based on various metrics. For example, you can set a target CPU utilization percentage and specify the desired minimum and maximum number of replicas.
Integration with Metrics APIs
- HPA interacts with the Kubernetes Metrics API to gather metric values. For CPU utilization, it uses metrics provided by the
metrics.k8s.ioAPI. For custom metrics, you need to set up custom metrics APIs or use external metrics providers.
Autoscaling Algorithms
- HPA supports different scaling algorithms, such as average or resource-based scaling. The scaling algorithm determines how the desired number of replicas is calculated based on the observed metric values.
Example HPA Configuration
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-deployment
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
In this example,
The HPA is named
my-hpaand targets themy-deploymentdeployment.It’s configured to maintain a minimum of 2 replicas and scale up to a maximum of 10 replicas.
Scaling decisions are based on CPU utilization, with a target average utilization of 50%.
Steps to enable HPA
Ensure the Metrics Server is running
- Metrics Server is a component that collects and exposes resource usage metrics in the cluster. Ensure it is deployed and running.
Add Resource Metrics to Pods
- For CPU-based scaling, make sure your pods have resource requests and limits defined for the CPU. HPA uses these values to make scaling decisions.
Deploy HPA Resource Configuration
- Apply the HPA configuration using
kubectl apply -f hpa-config.yaml.
Monitor HPA events
- Monitor HPA events using
kubectl get hpaandkubectl describe hpa my-hpa.
So what can we conclude from this?
Your application will respond more quickly to variations in load and resource requirements when it uses HPA, which enables automatic scaling depending on metrics that are observed. By leveraging the benefits of HPA, Kubernetes users can achieve a more responsive, efficient, and cost-effective deployment strategy for their applications. It’s a valuable tool for ensuring that applications scale dynamically in line with changing demands and resource requirements.